Section:
New Results
Comparing Methods for Assessment of Facial Dynamics in Patients with Major Neurocognitive Disorders
Participants :
Yaohui Wang, Antitza Dantcheva, Francois Brémond.
Keywords: Face Analysis
Assessing facial dynamics in patients with major neurocognitive disorders and specifically with Alzheimer's disease (AD) has shown to be highly challenging. Classically such assessment is performed by clinical staff, evaluating verbal and non-verbal language of AD-patients, since they have lost a substantial amount of their cognitive capacity, and hence communication ability. In addition, patients need to communicate important messages, such as discomfort or pain. Automated methods would support the current healthcare system by allowing for telemedicine, i.e., lesser costly and logistically inconvenient examination.
In this work [52], we compare methods for assessing facial dynamics such as talking, singing, neutral and smiling in AD-patients, captured during music mnemotherapy sessions. Specifically, we compare 3D ConvNets (see Figure 21), Very Deep Neural Network based Two-Stream ConvNets (see Figure 22), as well as Improved Dense Trajectories. We have adapted these methods from prominent action recognition methods and our promising results suggest that the methods generalize well to the context of facial dynamics.
The Two-Stream ConvNets in combination with ResNet-152 obtains the best performance on our dataset (Table 3), capturing well even minor facial dynamics and has thus sparked high interest in the medical community.
Figure
21. C3D based facial dynamics detection: For each video sequence, faces are detected and the face sequences are passed into a pre-trained C3D network to extract a 4096-dim feature vector for each video. Finally a SVM classifier is trained to predict the final classification result. We have blurred the faces of the subject in this figure, in order to preserve the patient's privacy.
|
|
Figure
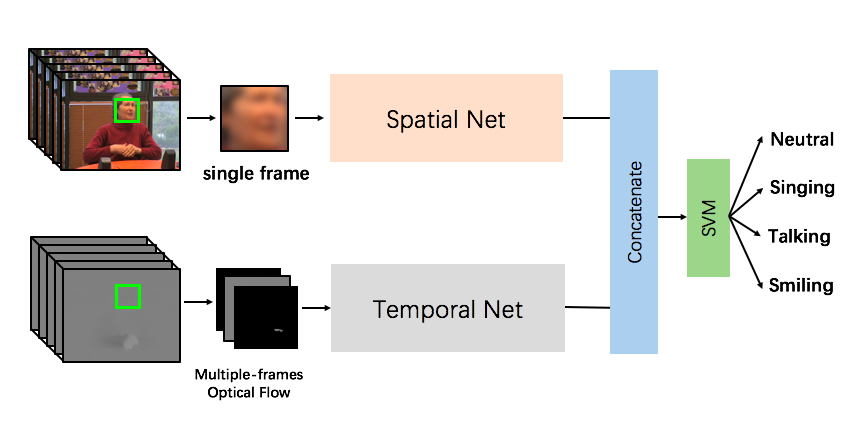
22. (a) While the spatial ConvNet accepts a single frame as input, the temporal ConvNet's input is the and of 10
consecutive frames, namely 20 input channels. Both described inputs are fed
into the Two-stream ConvNets, respectively. We use in this work two variations
of Very Deep Two Stream ConvNets, incorporating VGG-16 [76]
ResNet-152 [65] for both streams respectively.
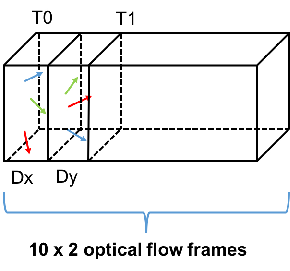
(b) The optical flow of each frame has two components, namely and
. We stack 10 times after for each frame to form a 20 frames length input volume.
|
| (a) Two-Stream Architecture |
|
|
| (b) Stacked Optical Flow Field volume |
|
Table
3. Classification accuracies of C3D, Very Deep Two-Stream ConvNets, iDT, as well as fusion thereof on the presented ADP-dataset. We report the Mean Accuracy (MA) associated to the compared methods. Abbreviations used: SN...Spatial Net, TN...Temporal Net.
|
Method
|
MA (%)
|
| C3D |
67.4 |
| SN of Two-Stream ConvNets (VGG-16) |
65.2 |
| TN of Two-Stream ConvNets (VGG-16) |
69.9 |
| Two-Stream ConvNets (VGG-16) |
76.1 |
| SN of Two-Stream ConvNets (ResNet-152) |
69.6 |
| TN of Two-Stream ConvNets (ResNet-152) |
75.8 |
| Two-Stream ConvNets (ResNet-152) |
76.4 |
| iDT |
61.2 |
| C3D + iDT |
71.1 |
| Two-Stream ConvNets (VGG-16) + iDT |
78.9 |
| Two-Stream ConvNets (ResNet-152) + iDT |
79.5
|


